 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking as Compression: Your Reasoning Model is Secretly a Context Compressor
May 27, 2026Context compression aims to shorten long context inputs with minimal information loss for LLM inference acceleration. While existing methods have shown promise, they typically rely on complex compression modules or compression-specific training, leaving the intrinsic capabilities of LLMs underexplored. In contrast, this work reveals that a thinking model itself can naturally compress long contexts by organizing task-relevant information. We thus derive Thinking as Compression (TaC), a new compression paradigm that treats thinking itself as compressed context. Without relying on specific dedicated compressor, TaC directly prompts the thinking model to generate thinking traces as the shortened context, already outperforming most representative compression methods. Further, given that raw thinking output may struggle with budget control and shortcut behaviors, we introduce Thinking as Compression Constrained (TaC-C), leveraging a simple reward-driven optimization framework to elicit intrinsic thinking as compact and controllable compressed context. Experiments across four long-context QA benchmarks demonstrate that TaC-C consistently outperforms existing baselines. At 4x and 8x compression ratios, it surpasses the strongest competitor by 17.4% and 23.4% in average F1, and by 15.7% and 21.7% in average Exact Match Score (EM), respectively.
Self-Distilled Trajectory-Aware Boltzmann Modeling: Bridging the Training-Inference Discrepancy in Diffusion Language Models
May 12, 2026Diffusion Language Models (DLMs) have recently emerged as a promising alternative to autoregressive language models, offering stronger global awareness and highly parallel generation. However, post-training DLMs with standard Negative Evidence Lower Bound (NELBO)-based supervised fine-tuning remains inefficient: training reconstructs randomly masked tokens in a single step, whereas inference follows a confidence-guided, multi-step easy-to-hard denoising trajectory. Recent trajectory-based self-distillation methods exploit such inference trajectories mainly for sampling-step compression and acceleration, often improving decoding efficiency without substantially enhancing the model's underlying capability, and may even degrade performance under full diffusion decoding. In this work, we ask whether self-distilled trajectories can be used not merely for faster inference, but for genuine knowledge acquisition. Although these trajectories lie on the pretrained DLM's own distributional manifold and thus offer a potentially lower optimization barrier, we find that naively fine-tuning on them with standard NELBO objectives yields only marginal gains. To address this limitation, we propose \textbf{T}rajectory-\textbf{A}ligned optimization via \textbf{Bo}ltzmann \textbf{M}odeling (\textbf{TABOM}), a self-distilled trajectory-based post-training framework that aligns training with the easy-to-hard structure of inference. TABOM models the inference unmasking preference as a Boltzmann distribution over predictive entropies and derives a tractable pairwise ranking objective to align the model's certainty ordering with the observed decoding trajectory. Empirically, TABOM achieves substantial gains in new domains, expands the effective knowledge boundary of DLMs, and significantly mitigates catastrophic forgetting compared with standard SFT.
Task-Aware LLM Routing with Multi-Level Task-Profile-Guided Data Synthesis for Cold-Start Scenarios
Apr 10, 2026Large language models (LLMs) exhibit substantial variability in performance and computational cost across tasks and queries, motivating routing systems that select models to meet user-specific cost-performance trade-offs. However, existing routers generalize poorly in cold-start scenarios where in-domain training data is unavailable. We address this limitation with a multi-level task-profile-guided data synthesis framework that constructs a hierarchical task taxonomy and produces diverse question-answer pairs to approximate the test-time query distribution. Building on this, we introduce TRouter, a task-type-aware router approach that models query-conditioned cost and performance via latent task-type variables, with prior regularization derived from the synthesized task taxonomy. This design enhances TRouter's routing utility under both cold-start and in-domain settings. Across multiple benchmarks, we show that our synthesis framework alleviates cold-start issues and that TRouter delivers effective LLM routing.
Beyond Heuristic Prompting: A Concept-Guided Bayesian Framework for Zero-Shot Image Recognition
Mar 09, 2026Vision-Language Models (VLMs), such as CLIP, have significantly advanced zero-shot image recognition. However, their performance remains limited by suboptimal prompt engineering and poor adaptability to target classes. While recent methods attempt to improve prompts through diverse class descriptions, they often rely on heuristic designs, lack versatility, and are vulnerable to outlier prompts. This paper enhances prompt by incorporating class-specific concepts. By treating concepts as latent variables, we rethink zero-shot image classification from a Bayesian perspective, casting prediction as marginalization over the concept space, where each concept is weighted by a prior and a test-image conditioned likelihood. This formulation underscores the importance of both a well-structured concept proposal distribution and the refinement of concept priors. To construct an expressive and efficient proposal distribution, we introduce a multi-stage concept synthesis pipeline driven by LLMs to generate discriminative and compositional concepts, followed by a Determinantal Point Process to enforce diversity. To mitigate the influence of outlier concepts, we propose a training-free, adaptive soft-trim likelihood, which attenuates their impact in a single forward pass. We further provide robustness guarantees and derive multi-class excess risk bounds for our framework. Extensive experiments demonstrate that our method consistently outperforms state-of-the-art approaches, validating its effectiveness in zero-shot image classification. Our code is available at https://github.com/less-and-less-bugs/CGBC.
When Less is More: The LLM Scaling Paradox in Context Compression
Feb 10, 2026Scaling up model parameters has long been a prevalent training paradigm driven by the assumption that larger models yield superior generation capabilities. However, under lossy context compression in a compressor-decoder setup, we observe a Size-Fidelity Paradox: increasing the compressor size can lessen the faithfulness of reconstructed contexts though training loss decreases. Through extensive experiments across models from 0.6B to 90B, we coin this paradox arising from two dominant factors: 1) knowledge overwriting: larger models increasingly replace source facts with their own prior beliefs, e.g., ``the white strawberry'' $\to$ ``the red strawberry''; and 2) semantic drift: larger models tend to paraphrase or restructure content instead of reproducing it verbatim, e.g., ``Alice hit Bob'' $\to$ ``Bob hit Alice''. By holding model size fixed, we reflect on the emergent properties of compressed context representations. We show that the culprit is not parameter count itself, but the excessive semantic capacity and amplified generative uncertainty that accompany scaling. Specifically, the increased rank of context embeddings facilitates prior knowledge intrusion, whereas higher entropy over token prediction distributions promotes rewriting. Our results complement existing evaluations over context compression paradigm, underpinning a breakdown in scaling laws for faithful preservation in open-ended generation.
Efficient Medical Image Restoration via Reliability Guided Learning in Frequency Domain
Apr 15, 2025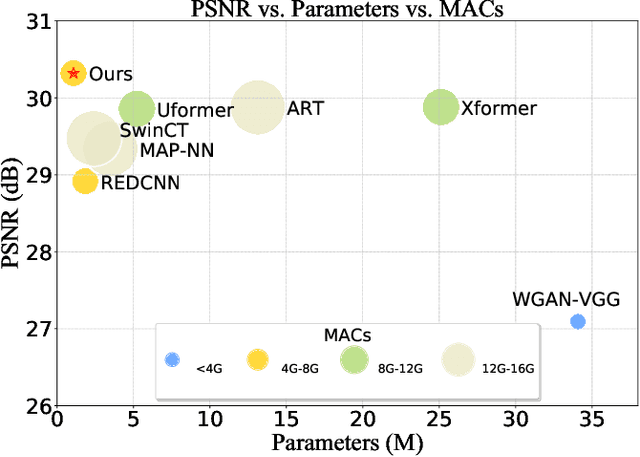
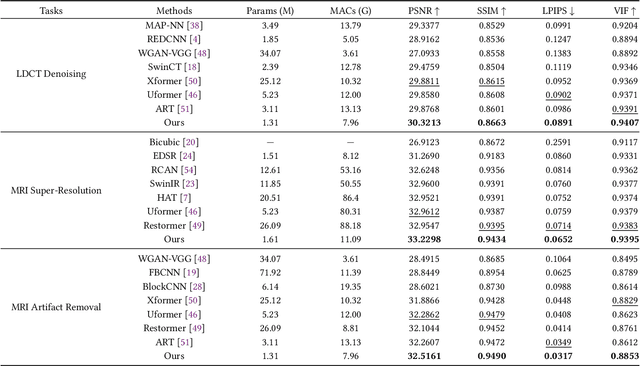
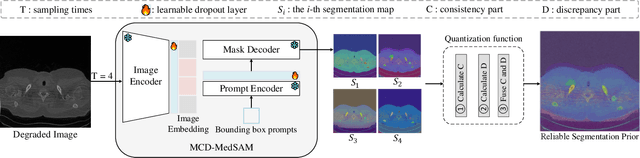
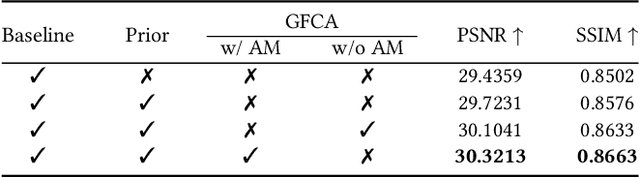
Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.
Disentangling Instruction Influence in Diffusion Transformers for Parallel Multi-Instruction-Guided Image Editing
Apr 07, 2025



Instruction-guided image editing enables users to specify modifications using natural language, offering more flexibility and control. Among existing frameworks, Diffusion Transformers (DiTs) outperform U-Net-based diffusion models in scalability and performance. However, while real-world scenarios often require concurrent execution of multiple instructions, step-by-step editing suffers from accumulated errors and degraded quality, and integrating multiple instructions with a single prompt usually results in incomplete edits due to instruction conflicts. We propose Instruction Influence Disentanglement (IID), a novel framework enabling parallel execution of multiple instructions in a single denoising process, designed for DiT-based models. By analyzing self-attention mechanisms in DiTs, we identify distinctive attention patterns in multi-instruction settings and derive instruction-specific attention masks to disentangle each instruction's influence. These masks guide the editing process to ensure localized modifications while preserving consistency in non-edited regions. Extensive experiments on open-source and custom datasets demonstrate that IID reduces diffusion steps while improving fidelity and instruction completion compared to existing baselines. The codes will be publicly released upon the acceptance of the paper.
SPACE: SPike-Aware Consistency Enhancement for Test-Time Adaptation in Spiking Neural Networks
Apr 03, 2025



Spiking Neural Networks (SNNs), as a biologically plausible alternative to Artificial Neural Networks (ANNs), have demonstrated advantages in terms of energy efficiency, temporal processing, and biological plausibility. However, SNNs are highly sensitive to distribution shifts, which can significantly degrade their performance in real-world scenarios. Traditional test-time adaptation (TTA) methods designed for ANNs often fail to address the unique computational dynamics of SNNs, such as sparsity and temporal spiking behavior. To address these challenges, we propose $\textbf{SP}$ike-$\textbf{A}$ware $\textbf{C}$onsistency $\textbf{E}$nhancement (SPACE), the first source-free and single-instance TTA method specifically designed for SNNs. SPACE leverages the inherent spike dynamics of SNNs to maximize the consistency of spike-behavior-based local feature maps across augmented versions of a single test sample, enabling robust adaptation without requiring source data. We evaluate SPACE on multiple datasets, including CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and DVS Gesture-C. Furthermore, SPACE demonstrates strong generalization across different model architectures, achieving consistent performance improvements on both VGG9 and ResNet11. Experimental results show that SPACE outperforms state-of-the-art methods, highlighting its effectiveness and robustness in real-world settings.
Test-time Adaptation for Foundation Medical Segmentation Model without Parametric Updates
Apr 02, 2025Foundation medical segmentation models, with MedSAM being the most popular, have achieved promising performance across organs and lesions. However, MedSAM still suffers from compromised performance on specific lesions with intricate structures and appearance, as well as bounding box prompt-induced perturbations. Although current test-time adaptation (TTA) methods for medical image segmentation may tackle this issue, partial (e.g., batch normalization) or whole parametric updates restrict their effectiveness due to limited update signals or catastrophic forgetting in large models. Meanwhile, these approaches ignore the computational complexity during adaptation, which is particularly significant for modern foundation models. To this end, our theoretical analyses reveal that directly refining image embeddings is feasible to approach the same goal as parametric updates under the MedSAM architecture, which enables us to realize high computational efficiency and segmentation performance without the risk of catastrophic forgetting. Under this framework, we propose to encourage maximizing factorized conditional probabilities of the posterior prediction probability using a proposed distribution-approximated latent conditional random field loss combined with an entropy minimization loss. Experiments show that we achieve about 3\% Dice score improvements across three datasets while reducing computational complexity by over 7 times.
Enhancing Zero-Shot Image Recognition in Vision-Language Models through Human-like Concept Guidance
Mar 21, 2025



In zero-shot image recognition tasks, humans demonstrate remarkable flexibility in classifying unseen categories by composing known simpler concepts. However, existing vision-language models (VLMs), despite achieving significant progress through large-scale natural language supervision, often underperform in real-world applications because of sub-optimal prompt engineering and the inability to adapt effectively to target classes. To address these issues, we propose a Concept-guided Human-like Bayesian Reasoning (CHBR) framework. Grounded in Bayes' theorem, CHBR models the concept used in human image recognition as latent variables and formulates this task by summing across potential concepts, weighted by a prior distribution and a likelihood function. To tackle the intractable computation over an infinite concept space, we introduce an importance sampling algorithm that iteratively prompts large language models (LLMs) to generate discriminative concepts, emphasizing inter-class differences. We further propose three heuristic approaches involving Average Likelihood, Confidence Likelihood, and Test Time Augmentation (TTA) Likelihood, which dynamically refine the combination of concepts based on the test image. Extensive evaluations across fifteen datasets demonstrate that CHBR consistently outperforms existing state-of-the-art zero-shot generalization methods.